
Jan 31, 2023
Bayer Grants4Tech 2022: CarbonStock
2022 CarbonStock Grants4Tech challenge, an annual external Bayer program designed to foster innovation, this year focusing on the science of carbon
Our teams continue to lead the way in developing our own innovative process models. These include crop development, evapotranspiration, soil moisture dynamics, nitrogen uptake by the crop, and quantitative precipitation estimates.

Modeling agricultural systems, such as crop production, from biological, physical and/or chemical principles can be traced back to the 1950s and 1960s. The models used were “process models,” which are mathematical abstractions that explicitly describe a system’s behavior and how it reacts to external drivers. Beginning in the 1960s, agriculture experienced an upsurge in the amount of data collected on and off the farms, leading to the emergence of empirical modeling frameworks, which were purely statistical. Instead of explicitly modeling the biophysics of a system, the statistical model correlated key “explanatory” variables with key system output(s). For example, statistical models began to be used in the 1960s to estimate yield using weather as an explanatory variable (Jones et al., 2017).
Unlike process models, prediction using statistical models is constrained by the domain of the explanatory variables. That is, statistical models can result in poor or not very useful “out-of-sample” predictions where the values of explanatory variables, such as weather conditions, soil properties, or management practices are outside the ranges used to train the statistical model. For example, a statistical model that had only been trained on corn yield data under ideal soil moisture conditions will likely give poor predictions under other soil moisture conditions. Plus, building a robust statistical model, as we have experienced from collecting experimental data on Climate LLC Research Farms, requires collecting a large number of soil samples from multiple plots over every field and throughout the year. This is not feasible or economically sound for the average farmer. Because a process model generally does not suffer from gaps in its inputs, it offers a great alternative to the statistical model. For the soil moisture example, the model will be run with multiple initial conditions covering a comprehensive range of soil moisture values that reflect the conditions of an entire geographical region, such as the Midwest, and an entire weather profile that includes droughts and wet years.
At Climate LLC, we both build our own process models and use models created by third parties. Our teams continue to lead the way in developing our own innovative process models. These include crop development, evapotranspiration, soil moisture dynamics, nitrogen uptake by the crop, and quantitative precipitation estimates. Figure 1 includes a diagram of the process model that underlies the nitrogen management tool in FieldView™ - a digital agriculture tool built by data scientists and engineers I work with everyday - that farmers use throughout the season to optimize their inputs in a sustainable way.
In the case of this digital tool, we explicitly model biochemical processes that control available nitrogen for crop uptake. Each process is modeled using a set of different equations with soil temperature, soil moisture, water flow, and depth as inputs. An example of a third-party process model we use is a short-term “numerical” weather forecasting model, which is used as input to our soil moisture models.
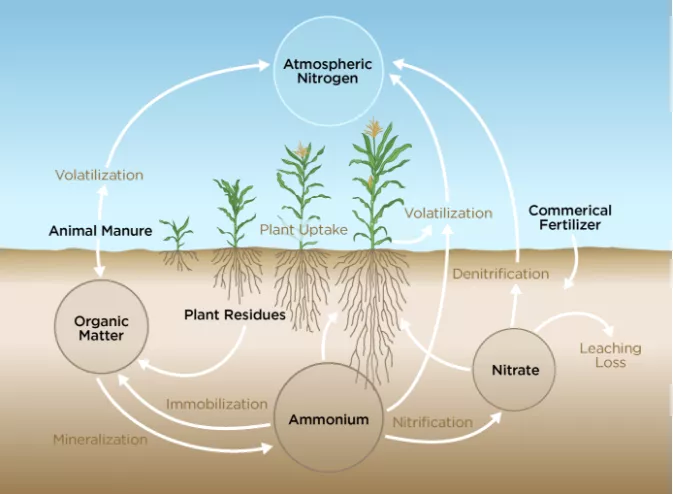
Figure 1: Nitrogen available for plant uptake can be modeled as a system of interacting biogeochemical processes that take many inputs, including soil temperature, soil moisture, water flow, and depth.
Regardless of the use case, the ultimate test of a model’s performance is its consistency with observed data. Agricultural systems are very complex, and we have yet to come across an agricultural process model that does not have a discrepancy with observed data in one form or another. Discrepancy with observed data is not unique to agricultural process models; it is a common challenge with process models in any field. Quantifying the model’s discrepancy and identifying its sources are key to improving the model, and thus, improving scientific understanding and decisions that are based upon it. But even after iterative improvements of the model structure and its input values a stubborn discrepancy, with an unidentified source, may remain.
Data assimilation is a powerful framework for combining observed data with the process model to obtain a more accurate representation of the real-world process. It can be used to estimate model discrepancy, account for the measurement error in the observations, and produce model output that is more consistent with system under consideration. It is vital to ensure that assimilated observed data do not have systematic errors or other biases of their own. If such biases are present, data assimilation will propagate them into the results.
For example, assimilating observations from a faulty rain gauge with a radar-based quantitative precipitation estimation (QPE) process model will not get the estimate any closer to reality and will likely instead worsen the estimation error. If a significant underestimate of rainfall is calculated by the QPE model and then fed to the soil moisture process model within our nitrogen tool, it could result in the tool forecasting normal nitrogen levels in the soil, when in fact it should have calculated a loss of nitrogen (due to leaching). Consequently, a grower would miss out on a sidedress application opportunity and ultimately on yield - which impacts their bottom line. If, on the other hand, rainfall is overestimated by the QPE model, the nitrogen tool could recommend more sidedress nitrogen to counteract the erroneously forecast losses, leading to increasing the financial cost of the farmer’s operation without increasing yield. Therefore, our researchers are careful and strategic in both defining the QPE model structure and quality-controlling the weather station observations assimilated with it. The result is rainfall estimates that are the state-of-the-art in the ag industry.
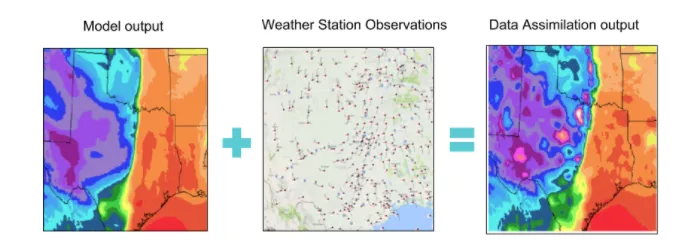
Figure 2: Data assimilation is a framework that combines observed data with the process model to obtain a more accurate representation of the real-world process. Data assimilation is commonly used with numerical weather models as illustrated here.
But is data assimilation always feasible and successful? In this age of Big Data (from ground-based sensors, weather stations, satellites, etc.), one could suggest we can get enough observations for data assimilation and make our process models a perfect representation of reality, right? Not exactly! Data is abundant, but it does have gaps. Commonly those gaps are in locations (in space, time and other model dimensions) where model output uncertainty is quite large. Filling those gaps is often a costly endeavor. So it is not a matter of how much data, but of other factors, such as where, when (during the growing season) and under what conditions they were collected -- and of what quality. As scientists, we must be vigilant and appropriately quantify uncertainty in data and models because the quality of our insights, and therefore our recommendations, depend on the data and models that power them.
Big Data, exponential growth in computational power, and advancements in empirical (statistical and, more recently, machine learning) algorithms are promising to unlock scientific insights at an unprecedented rate. However, the sophistication of these algorithms comes with some loss in the scientific understanding of the systems they are modeling -- after all, empirical models are not concerned with explaining the system’s mechanisms, only correlations among its inputs and output(s). As both data and process models continue to grow and evolve, an exciting direction for the understanding of agricultural systems is using process models as important features of statistical and machine learning algorithms to aid in obtaining meaningful out-of-sample/extrapolation results. By doing so, we can stand firmly on scientific principles and let the data take us further. Future knowledge belongs to those who develop the most effective models to unlock new insights from existing data.
Reference
J.W. Jones, J.M. Antle, B. Basso, K.J. Boote, R.T. Conant, I. Foster, H.C.J. Godfray, M.Herrero, R.E. Howitt, S. Janssen, B.A. Keating, R. Munoz-Carpena, C.H. Porter, C. Rosenzweig, T.R. Wheeler (2017) Brief history of agricultural systems modeling. Agricultural Systems, 155, pp. 240-254


2022 CarbonStock Grants4Tech challenge, an annual external Bayer program designed to foster innovation, this year focusing on the science of carbon

I couldn’t be happier than to have spent my summer focusing on a Climate FieldView™ feature project that will deliver a ton of value to farmers around the world by streamlining a small, but critical, part of the planting process.