
Jan 31, 2023
Bayer Grants4Tech 2022: CarbonStock
2022 CarbonStock Grants4Tech challenge, an annual external Bayer program designed to foster innovation, this year focusing on the science of carbon
At Climate LLC, our machine learning Data Scientists are exploring the potential of GANs in our disease identification model.

With hundreds of variations in publications, Generative Adversarial Networks, or GANs, have been creating a big wave in the AI and machine learning research community since their invention by Ian Goodfellow in 2014. Yann Lecun, vice president and chief AI scientist for Facebook, and founding father of convolution neural networks (CNN), noted, “The (GAN) variations that are now being proposed is the most interesting idea in the last 10 years in machine learning.”
How can GANs help us develop better products and bring value to our customers? At Climate LLC, our machine learning Data Scientists are exploring the potential of GANs in our disease identification model.
An accurate, robust and generalized mobile phone camera-based disease identification model is necessary to deliver innovative new value to farmers who use our digital farming platform, FieldViewTM; however, several challenges stand in the way. Different data sources have different fields of view and lighting conditions, the availability of different disease types is imbalanced, and disease syndromes vary across environments, hybrids and stages.


Figure 1: Example of corn gray leaf spot (GLS) images exhibiting significantly different symptoms from two data sources: inoculated field (left) and regular research field (right)
Collecting enough images for each of these variations is nearly impossible, but a lack of data variations leads to undesirable model generalization. In order to improve model performance, many variations of data augmentation techniques have been adopted, including random cropping, horizontal flipping, and shearing. They can boost the model generalization, but the resulting augmented images are highly correlated with the original sample. This is where we can take advantage of GANs to generate practical disease images based on limited real disease information in our hands. GANs provide a good estimation of the real data distribution by randomly generating samples according to the true distribution. By doing this we are enriching our dataset and saving expensive efforts in manual imagery collection.


Figure 2: Generated disease images (top two rows) and real disease images (bottom two rows). The left figure corresponds to the stripe-like diseases, such as goss’ wilt, gray leaf spot and northern leaf blight, while the right figure shows dot-like diseases, such as eye spot and southern rust.
Another potential application of GANs in the disease ID model is to leverage for semi-supervised learning, which means we want to take advantage of a large amount of unlabelled disease images that we already have but have yet to use. In a supervised framework, like most CNN models, a label has to be associated with each data sample. In our case, we ask experts - pathologists with special domain knowledge - to label individual images for us. This is a time-consuming process with limited throughput. With a large amount of inexpensive acquired unlabelled data, GANs can be adopted to learn the representation and structural information to enhance the supervised model performance.
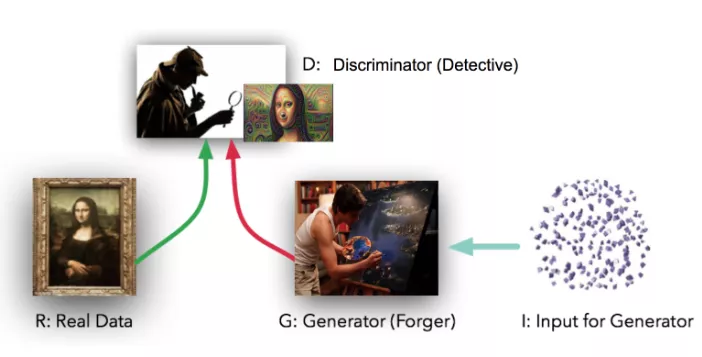
Figure 3: Illustration of GAN: with input as random noise, generator manages to fake the data to fool the discriminator who tries best to tell the fake from the real data. Figure is modified based on Dev Nag’s blog on medium.com*
Training vanilla GANs is a fairly heuristic process with obstacles such as unstable training, mode collapse, and gradient vanishing. Unstable training and mode collapse are the consequences of the flawed cost function which tries to optimize towards two opposite directions. Gradient vanishing is due to the non-overlapping supports between the true and generator distribution, which makes the distance between the two a constant. Therefore, we used Wasserstein-GAN(WGAN), a famous GANs variation, that enjoys stable training and good image quality. In order to convert the 100-d noise vector to an image size, several upsample steps are needed across different layers.
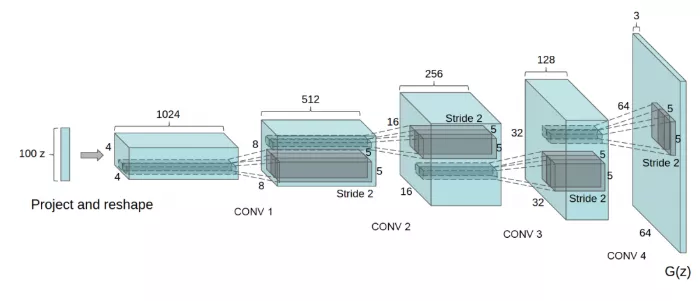
Figure 4: WGAN generator architecture, from ”Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks”
The WGAN discriminator is very similar to a typical CNN: The model takes the image as the input, feeds into many convolutional layers and outputs the prediction. The cost function of WGAN discriminator is Wasserstein distance rather than KL-divergence and JS-divergence that vanilla GANs use. Wasserstein distance is valid when the supports of two distributions are non-overlapping, which is exactly the scenario that GANs face. The discriminator in WGAN estimates the Wasserstein distance between true and generated distributions, while the generator tries to generate realist images to minimize such distance. Instead of the classification task that vanilla GANs discriminator conduct, WGAN discriminator actually performs a regression task. Such conversion proves to be very stable during the training, leading to a very encouraging generator performance.
As we introduced earlier, GANs can estimate the data distribution by generating data samples, enabling a better understanding of our data structure, and facilitating further mining of our data. Such exploration can lead to other GANs application, including semi-supervised learning.
Even though the unlabelled data couldn’t give a clear boundary of the final classification in a direct way, the underlying structure of the unlabelled data learned by GANs will help the classifier to gain more information when finding the boundaries of different classes. However, relevant literature only showed success in small image sizes, 64x64 pixels, and in disease modeling we target over 200x200 pixels, which can pose a big challenge on training the GANs. The necessity for a larger image is to identify details of disease symptoms and recognize the subtle differences. A larger image size will complicate the GANs model structure and manifest the unstable training, leading to unexpected model performance. An alternative is to use WGAN to support larger image sizes and more complicated architectures. Unfortunately, the discriminator in WGAN doesn’t act as a classifier. Instead, it tries to estimate the distance between the true data distribution and the generated data distribution, which is only suitable for generating realist images. Meaning, the motivation of the whole WGAN model doesn’t fit into the semi-supervised framework. We are actively monitoring GAN communities and are working for a solution.
Through all the detours, we learn that careful and thorough research needs to be carried out before we adopt any cutting-edge AI technology. We are not just AI executors, but rather AI strategists. The Data Scientists on our Geospatial Science Team and throughout Climate LLC are dedicated to delivering new features in the FieldView™ platform that benefit our customers by fusing cutting-edge AI technologies together with domain knowledge.

The photo above was taken during IPAM (Institute for Pure & Applied Mathematics) 2018 at UCLA, AI team members (from left to right: Ying She, Yann Lecun, Yaqi Chen and Yichuan Gui) sharing Climate LLC’s disease ID work and GANs efforts.
Reference
*Nag, Dev (2017) “Generative Adversarial Networks (GANs) in 50 lines of code (PyTorch)”
Retrieved from https://medium.com/@devnag/generative-adversarial-networks-gans-in-50-lines-of-code-pytorch-e81b79659e3f
* Radford, Alec & Metz, Luke (2016) “Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks”
Retrieved from https://arxiv.org/pdf/1511.06434.pdf
Yaqi Chen, Climate Geospatial Artificial Intelligence Research
Yaqi Chen is a Sr. Data Scientist in Machine Learning on the Geospatial Science team at Climate LLC. Prior to joining Climate in 2016, Yaqi worked as an Imaging Scientist for Monsanto. She has contributed several modeling efforts on mobile phone based foliar disease identification and is currently leading the deep learning imagery based in-season yield forecasting program through collaboration with Yield Analytics team.
Yaqi earned her doctoral degree from Washington University in St. Louis.
2022 CarbonStock Grants4Tech challenge, an annual external Bayer program designed to foster innovation, this year focusing on the science of carbon

Machine learning and optimization models are digitally connecting our R&D pipeline to maximize value for farmers and helping Bayer redesign the testing network.