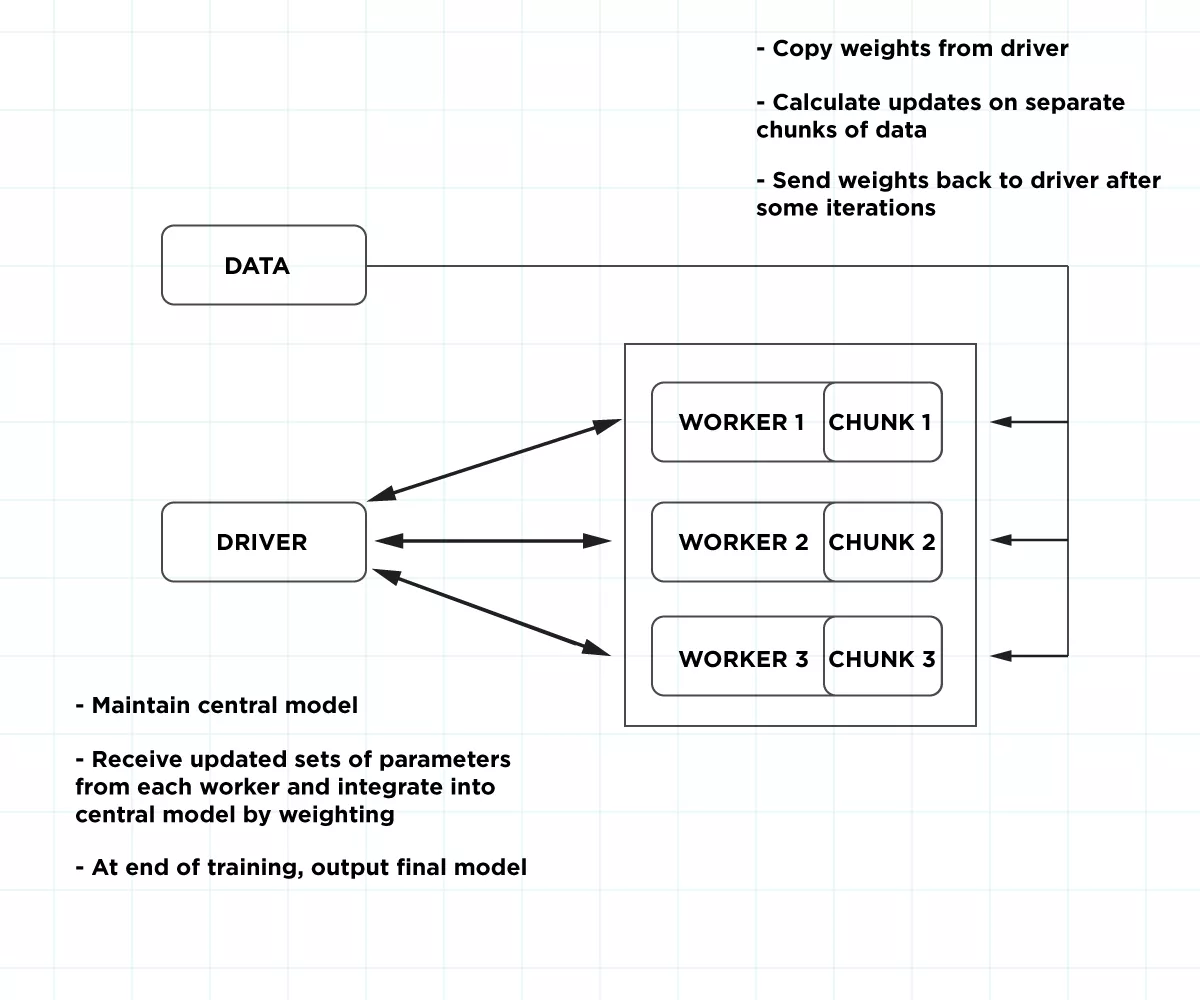
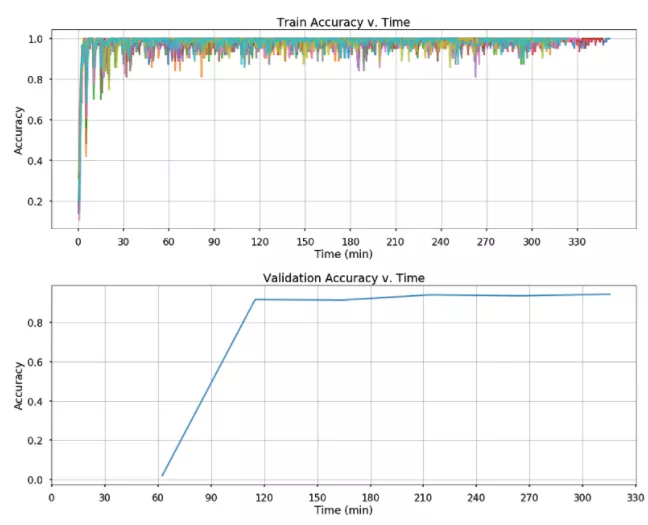
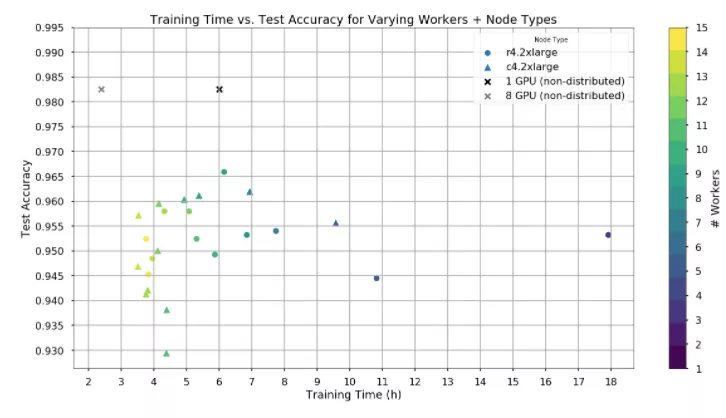
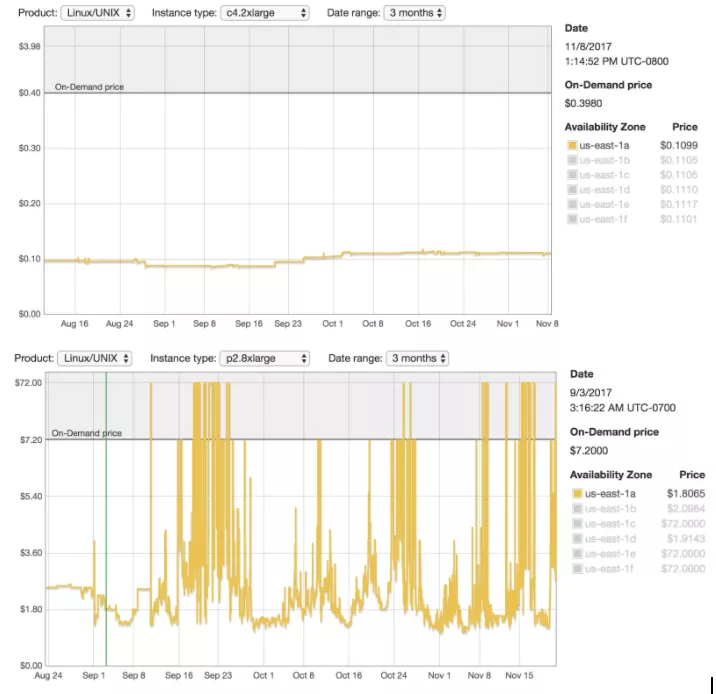
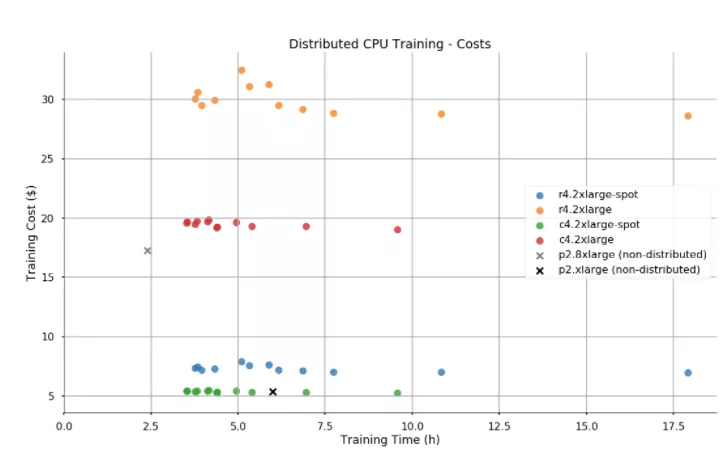
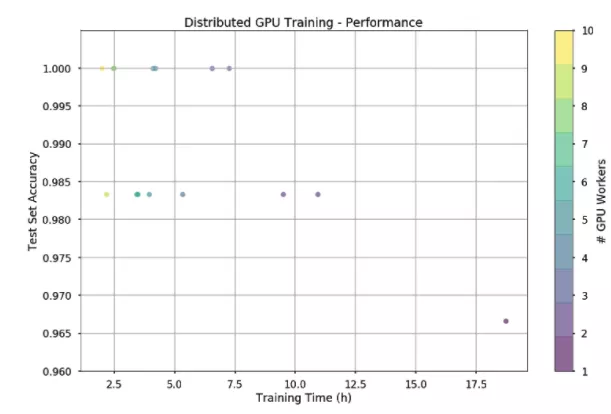
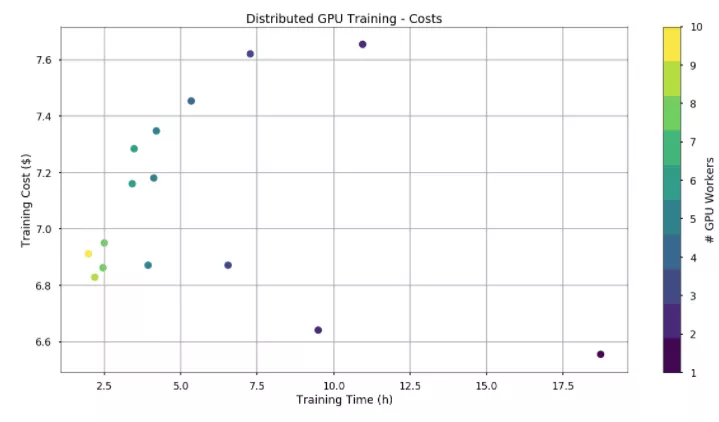
By the time we could train on GPU nodes, the spot price for a single GPU was around $0.32/hr (on-demand price is $0.9/hr). The cost of training varies by only $1. Interestingly, using more workers and training the model faster sometimes ends up costing less.
Distributed training is a valuable tool for us because it fits with the infrastructure that our team uses. Being able to build a pipeline on our Data Science Platform is critical given that data scientists often spend more time collecting and processing data rather than training models. This played a big role in our exploration of Distributed Keras in addition to considerations of training time, performance, and costs.
Join us as we explore and build Deep Learning tools to help all the world’s farmers sustainably increase their productivity with digital tools.