Solving many different agronomic problems with a few capabilities enables us to tackle higher-order problems. For example, every season growers must make crucial decisions about seeds and fertilizer for their fields. First, growers must decide what seed to plant on a field. Second, they must decide what fertilizer to apply at what times of the season. In machine learning speak, both problems must translate hundreds of features about a field and agronomic inputs into recommendations for what products to buy and how to use them in the field. These recommendations fit into the larger strategic context of fully integrated agriculture solutions that guide decision making via digital tools.
While the science of seed and fertilization is different, the key engineering insight is recognizing that production code executing recommendation models need not be duplicated for every model or require hand-crafted software stacks. On the contrary, we have learned that we can build a single generic recommendation capability that solves many recommendation problems. For example, a single generic recommendation capability can execute models for both seed hybrids and fertilizer applications, rather than needing stacks of code dedicated to each.
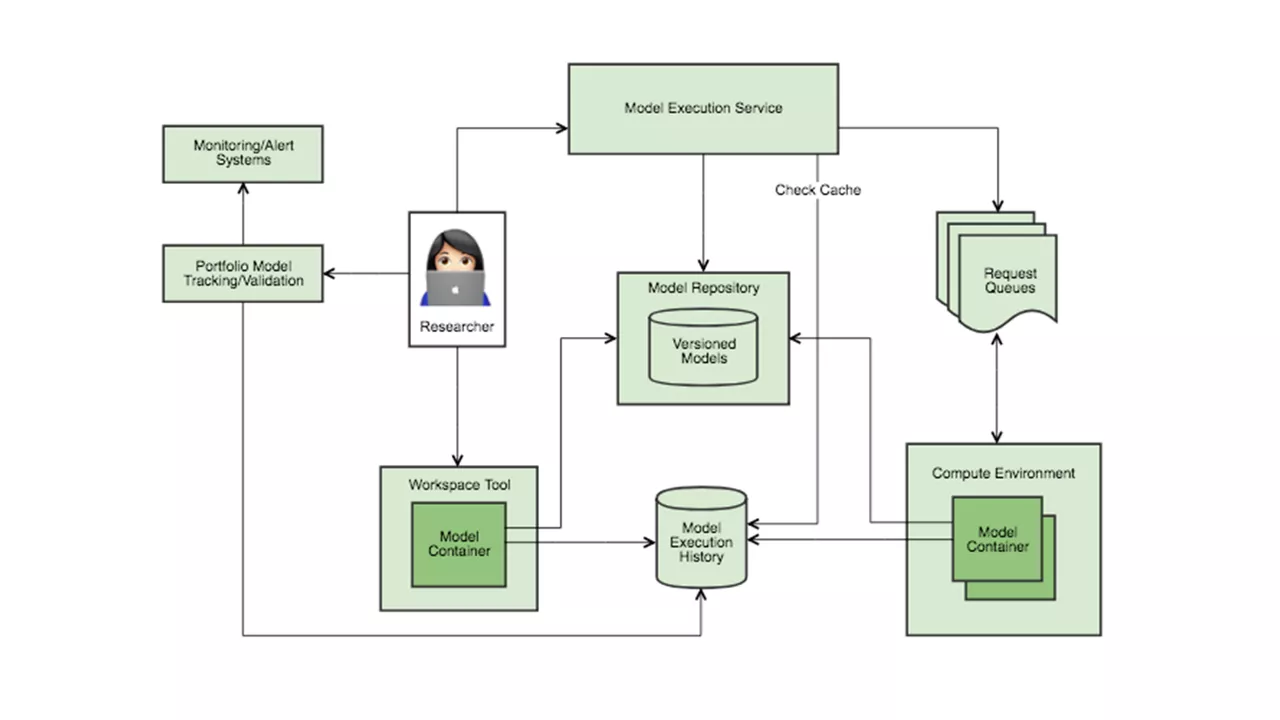
Our recommendation capability is generic, as it decouples agronomic model code and the production code stack that executes them. The capability can thus execute any model, provided its computational learning type is supported. By decoupling models from their underlying execution, we can organize all our models into model repositories. Organizing models in repositories enables us to solve otherwise difficult problems declaratively, such as versioning and cohort experimentation. Use of identifiers in the model repository provide runtime indirection and enable client invocation without assumptions about type or runtime for each model. In doing so, we are increasingly thinking about models in terms of metadata and beginning to apply ideas that originated from traditional metadata management.
So, let’s recap our journey so far, with seeds and fertilizers as our exemplar: